Linear Regression¶
Introduction¶
In statistics, linear regression is a linear approach to modeling the relationship between a scalar response (or dependent variable) and one or more explanatory variables (or independent variables). The case of one explanatory variable is called simple linear regression. For more than one explanatory variable, the process is called multiple linear regression. This term is distinct from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable.
The Simple Linear Regression Model¶
The simplest deterministic mathematical relationship between two variables \(x\) and \(y\) is a linear relationship: \(y = \beta_0 + \beta_1 x\).
The objective of this section is to develop an equivalent linear probabilistic model.
If the two (random) variables are probabilistically related, then for a fixed value of x, there is uncertainty in the value of the second variable.
So we assume \(Y = \beta_0 + \beta_1 x + \varepsilon\), where \(\varepsilon\) is a random variable.
Two variables are related linearly “on average” if for fixed x the actual value of Y differs from its expected value by a random amount (i.e. there is random error).
A Linear Probabilistic Model¶
Definition: (The Simple Linear Regression Model)
There are parameters \(\beta_0\), \(\beta_1\), and \(\sigma^2\), such that for any fixed value of the independent variable \(x\), the dependent variable is a random variable related to \(x\) through the model equation
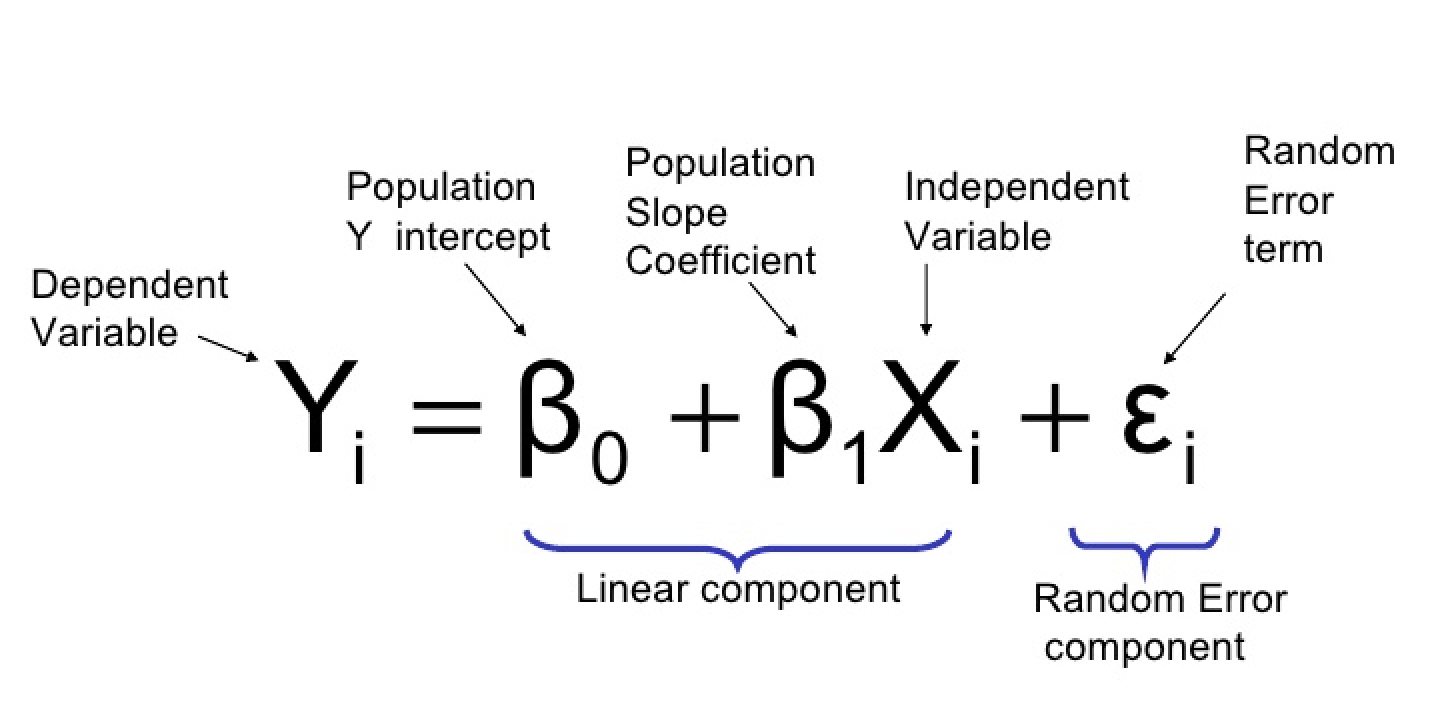
The quantity \(\varepsilon\) in the model equation is the “error” - a random variable, assumed to be symmetrically distributed with
(no assumption made about the distribution of \(\varepsilon\), yet)
- \(\boldsymbol{X}\): the independent, predictor, or explanatory variable (usually known).
- \(\boldsymbol{Y}\): the dependent or response variable. For fixed \(x\), \(Y\) will be random variable.
- \(\boldsymbol{\varepsilon}\): the random deviation or random error term. For fixed \(x\), \(\varepsilon\) will be random variable.
- \(\boldsymbol{\beta_0}\): the average value of \(Y\) when \(x\) is zero (the intercept of the true regression line)
- \(\boldsymbol{\beta_1}\): the expected (average) change in \(Y\) associated with a 1-unit increase in the value of \(x\). (the slope of the true regression line)
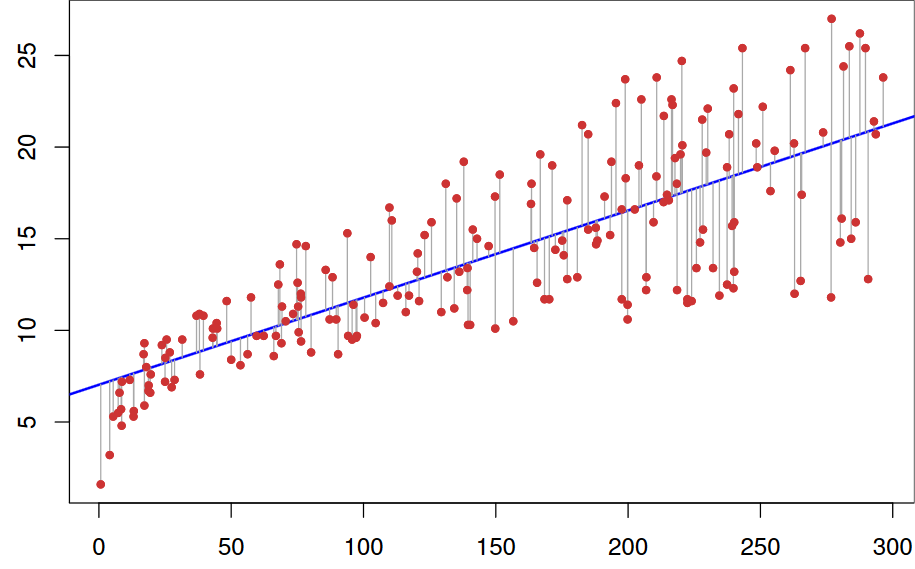
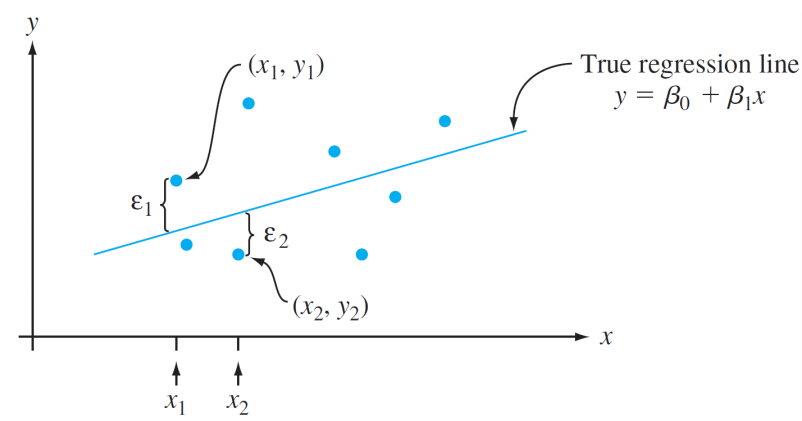
The points \((x_1, y_1),\dots,(x_n, y_n)\) resulting from \(n\) independent observations will then be scattered about the true regression line:
Estimating Model Parameters¶
The values of \(\beta_0\), \(beta_1\), and \(sigma\) will almost never be known to an investigator.
Instead, sample data consists of n observed pairs \((x_1, y_1),\dots,(x_n, y_n)\) from which the model parameters and the true regression line itself can be estimated.
The data (pairs) are assumed to have been obtained independently of one another.
The “best fit” line is motivated by the principle of least squares, which can be traced back to the German mathematician Gauss (1777–1855):
A line provides the best fit to the data if the sum of the squared vertical distances (deviations) from the observed points to that line is as small as it can be.
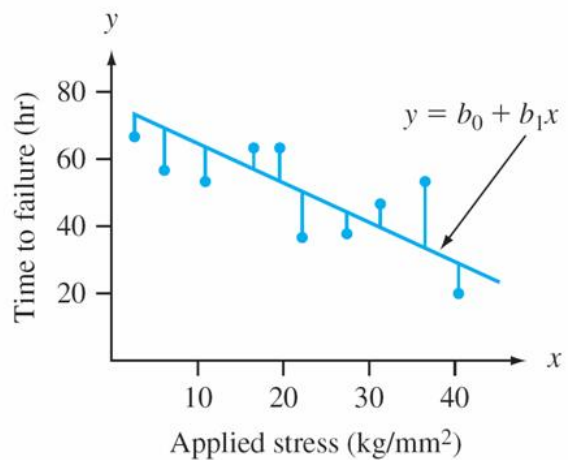
The sum of squared vertical deviations from the points \((x_1, y_1),\dots,(x_n, y_n)\)
The point estimates of \(\beta_0\) and \(\beta_1\), denoted by and, are called the least squares estimates – they are those values that minimize \(f(b_0, b_1)\).
The fitted regression line or least squares line is then the line whose equation is \(y=\hat{\beta}_{0}+\hat{\beta}_{1} x\).
The minimizing values of \(b_0\) and \(b_1\) are found by taking partial derivatives of \(f(b_0, b_1)\) with respect to both \(b_0\) and \(b_1\), equating them both to zero [analogously to \(f'(b)=0\) in univariate calculus], and solving the equations
The least squares estimate of the slope coefficient \(\beta_1\) of the true regression line is
Shortcut formulas for the numerator and denominator of \(\hat{\beta_1}\) are
The least squares estimate of the intercept \(b_0\) of the true regression line is
Usage¶
Imagine that we have following points and we want to build a linear regression model:
| X | Y |
|---|---|
| 1.0 | 1.0 |
| 2.0 | 2.0 |
| 3.0 | 1.3 |
| 4.0 | 3.75 |
| 5.0 | 2.25 |
Then the code will look like this:
// example_linear_regression.cpp
#include <iostream>
#include "../src/numerary.hpp" // Numerary library
using namespace std;
using namespace numerary;
/* The main function */
int main() {
const int N = 5; // Number of points
double *X = new double[N], *Y = new double[N], *predicted_kc = new double[2];
X[0] = 1.0; Y[0] = 1.0;
X[1] = 2.0; Y[1] = 2.0;
X[2] = 3.0; Y[2] = 1.3;
X[3] = 4.0; Y[3] = 3.75;
X[4] = 5.0; Y[4] = 2.25;
// Get predicted linear regression line
predicted_kc = Numerary::linear_regression(X, Y, N);
// Equation of regression line
cout << "y = " << predicted_kc[0] << "*x + " << predicted_kc[1] << endl;
// Reallocate memory
delete[] X;
delete[] Y;
delete[] predicted_kc;
return 0;
}